
大規模言語モデルの学習においては、実際の人間による評価をモデルの出力に反映させる「Reinforcement Learning from Human Feedback(RLHF)」が行われます。しかし、RLHFは実在の人間を使うため報酬の支払いでコストがかさんだり、フィードバックを回収するまでに時間がかかるなどの欠点が存在していました。「AlpacaFarm」は「人間がどんな評価を返すのか」をシミュレートすることで安価&高速にRLHFを進めることができるツールです。
仕事に役立つIT関連の最新ニュース
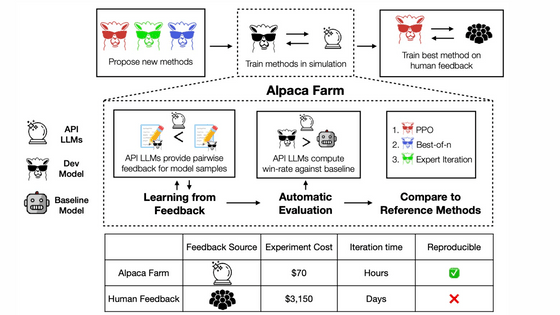
大規模言語モデルの学習においては、実際の人間による評価をモデルの出力に反映させる「Reinforcement Learning from Human Feedback(RLHF)」が行われます。しかし、RLHFは実在の人間を使うため報酬の支払いでコストがかさんだり、フィードバックを回収するまでに時間がかかるなどの欠点が存在していました。「AlpacaFarm」は「人間がどんな評価を返すのか」をシミュレートすることで安価&高速にRLHFを進めることができるツールです。